Travel, Tech, Thoughts…
-

VTT Editing – Simple Editors for Removing and Adding Content
I have a podcast I run with one of my brothers and a friend. We record the podcast via Zoom, which generates a transcript in VTT format with timestamps. Occasionally, we have an issue with the recording where we have some banter at the beginning of the podcast or something goes funky in the middle…
-

Best 3D Printed Sunglasses Clip for Car Visor
I’ve needed a place to put sunglasses in my car for years. My sunglasses have typically ended up in one of the cup holders. Recently, it dawned on me that I could print a clip or holder that would attach to my sun visor to hold my sunglasses. I looked at the various 3D design…
-

On the Future of Sociology
I had an interesting discussion a few days ago with my wife. We were talking about the futures of our disciplines (hers: genetic counseling; mine: sociology). I haven’t said this publicly before, but I’ve been thinking about it for a while. I don’t think sociology is long for academia. Before I go down this path,…
-

Redacting PDFs on Linux
I had an odd situation pop up where I needed to redact a PDF. It wasn’t anything nefarious or super exciting, but it did involve a complicated PDF that included images and tables in addition to text. In figuring out how to redact the PDF, I ended up learning a few things and thought it…
-

Fixing Zotero Corrupt Database Issue on Linux
I use Zotero to manage my references and have for decades since it was first developed. I’m a huge fan and teach all my students how to use it. But I also don’t follow one of the programmers’ recommendations on where to store my Zotero database. As soon as I install Zotero, I change the…
-

Kubuntu 25.04 – Reset Wayland
I just installed Kubuntu 25.04 on my laptop and started running into an issue. It started when I tried to load Spectacle to take a screenshot. Spectacle froze and so did my panel, but I could still hit Alt+F2 to open new programs. I could also use Alt+Tab to switch between non-frozen programs. I couldn’t…
-
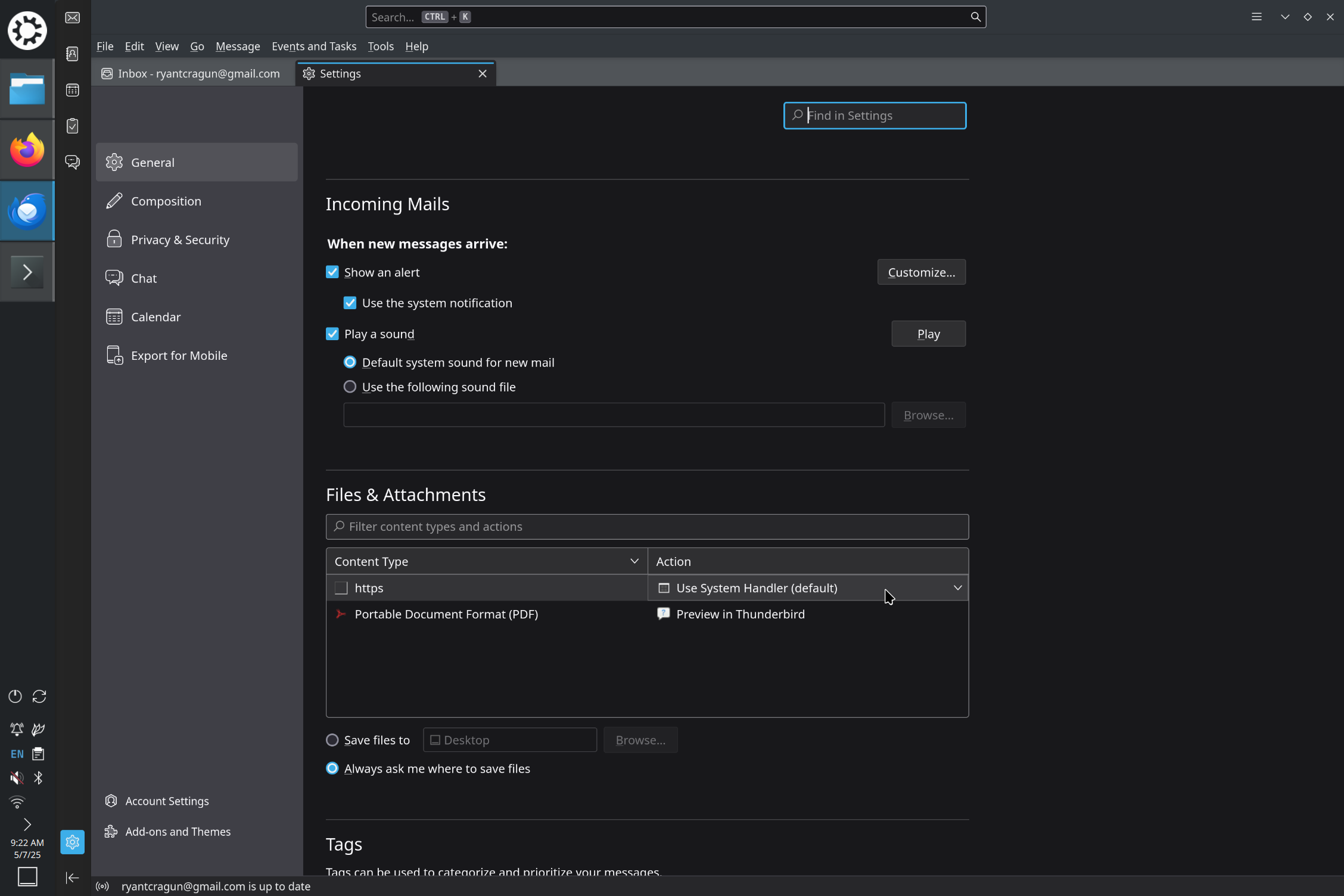
Changing Default Browser for Links in Thunderbird
I just reformatted my computer (I try to do that about once a year) to Kubuntu 25.04. That meant setting up Thunderbird (version 128.10.0esr) with my email again. I use Firefox as my default browser (because it respects privacy), but install Chromium as a backup for the occasional website that doesn’t work very well with…
-
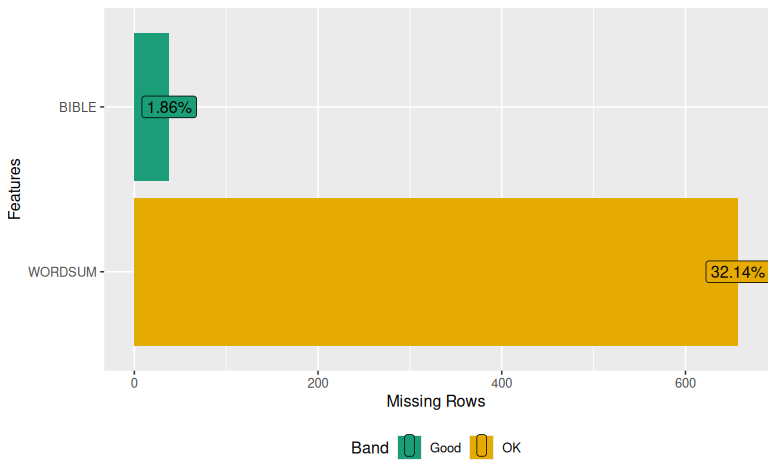
Imputing Missing Data in R – mice
I got a revise and resubmit on a recent paper. We noted that we had some missing data on some of the variables in our dataset. One of the reviewers suggested we address the missing data issue, which I have typically just managed using listwise/casewise deletion (a.k.a. complete-case analysis, which entails not including cases that…
-
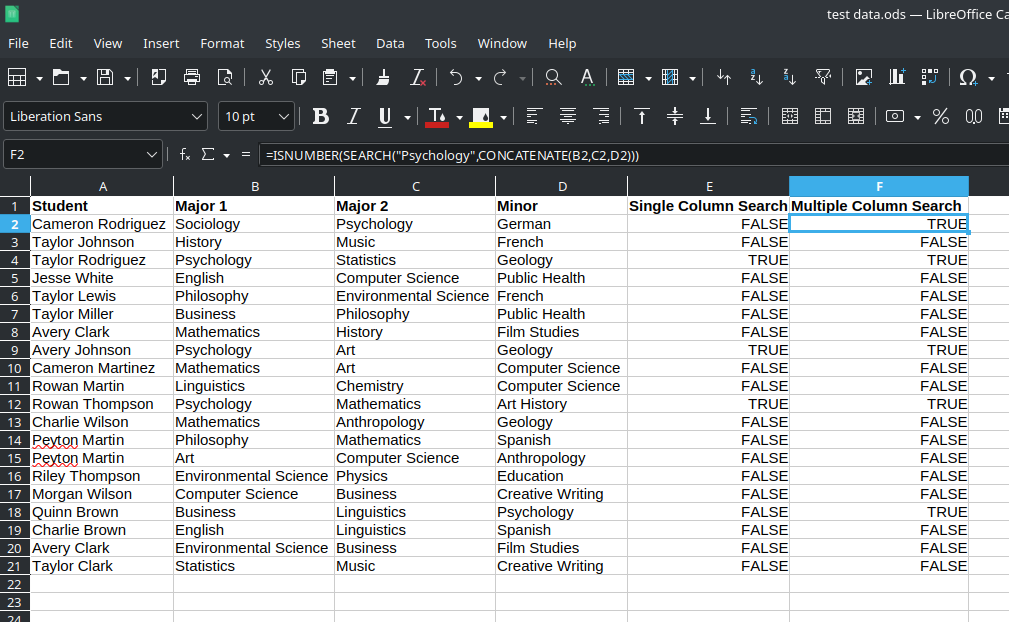
LibreOffice Calc – Search for Specific Text Across Columns
I have a task I am asked to do fairly regularly that involves searching through a large spreadsheet (around 4,000 rows with about a dozen columns) looking for very specific text. There are, of course, various ways I could accomplish this. But I finally found a solution that speeds this up and want to document…
-

Aruba – Jamanota
I was in Aruba for four days for a conference. I didn’t have a lot of free time but, after checking out all of the details of the highest point, I thought that I could skip lunch one day, climb the highest point, and still make it back for the next session. So, I tried…