Tag: Kubuntu
-
AppImage, Snap, and Flatpak on Kubuntu
I’m guessing most people who don’t use Linux have no idea how convenient repositories are. I’m a huge fan of how Linux has managed (and mostly continues to manage) software for quite a while: you open a console or the software manager on your computer, search for the software you want, and install it. The…
-
Kubuntu 25.04 – KRunner and iBus issues
Over the last month, I have updated the three computers I use to Kubuntu 25.04. On my laptop, I ran into an issue where Wayland would just periodically freeze. I figured out a solution to that and detailed it here. I finally installed Kubuntu 25.04 on my home desktop, which is the machine I use…
-

Getting Ollama and Open WebUI Working on Kubuntu 23.10
I have two specific use cases for setting up AI locally instead of using ChatGPT (for which I have a subscription as I use it for a variety of tasks, as does my wife). I needed to analyze interviews but couldn’t upload them to the web for security reasons. I also wanted to work on…
-
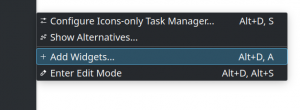
Kubuntu – KDE – adjusting screen brightness trick
I just happened upon an interesting little bonus feature in Kubuntu 22.04 with KDE Plasma 5.24.7 that I thought I’d share since it’s so nifty. It’s possible to add a battery icon to a panel. This is done by right-clicking on the panel and selecting “Add Widgets.” Scroll down and find the battery and brightness…
-
Kubuntu/Linux – batch convert HEIF images
My son recently went on a field trip. The teachers who went with him took hundreds of photos… on their iPhones. Since I want the photos of him, I downloaded all of them so I could skim through them and find the ones of my son. But I quickly realized that I was having issues…
-
Kubuntu 22.04 – Pending update of “firefox” snap
In the 22.04 version of Ubuntu/Kubuntu, Firefox was switched from a repository to a snap. I don’t know enough about the technical reasons for that, but it does mean that how Firefox is updated has changed. It also introduced a very annoying notification message that you’ve probably seen (and which is why you’re here: Switching…
-
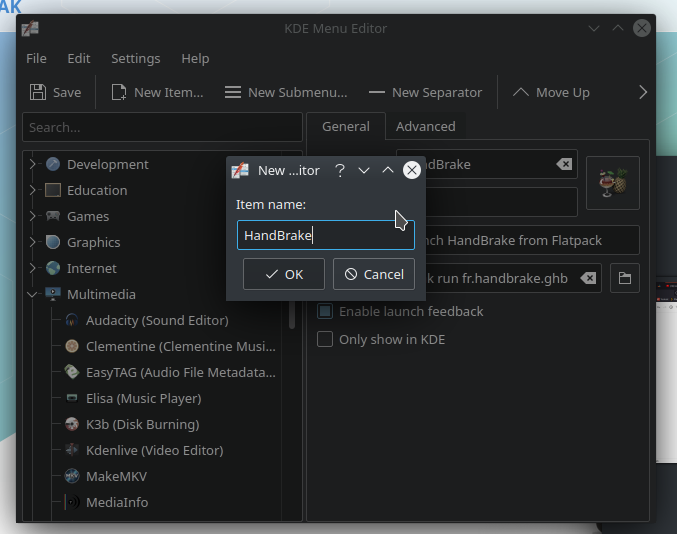
Launching HandBrake 1.4.0 in Kubuntu 21.04
The fine folks at HandBrake have updated their software and distribution system to a Flatpack approach. Their Flatpack for Linux is based on Gnome, not KDE, which is fine, but it does mean that the GUI is no longer skinned with my system settings on KDE. Oh well… The bigger issue is that, with a…
-
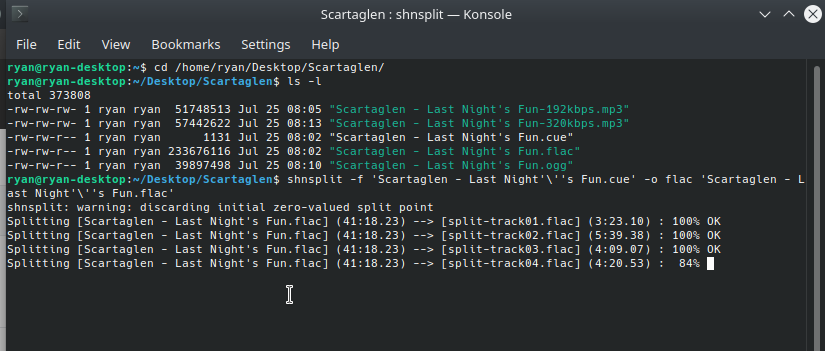
Kubuntu – Audio CD Ripping
I mostly buy digital audio these days. My preferred source is bandcamp as they provide files in FLAC (Free Lossless Audio Codec). However, I ended up buying a CD recently (Last Night’s Fun by Scartaglen) as there wasn’t a digital download available and, in the process, I realized that there are lots of options for…
-
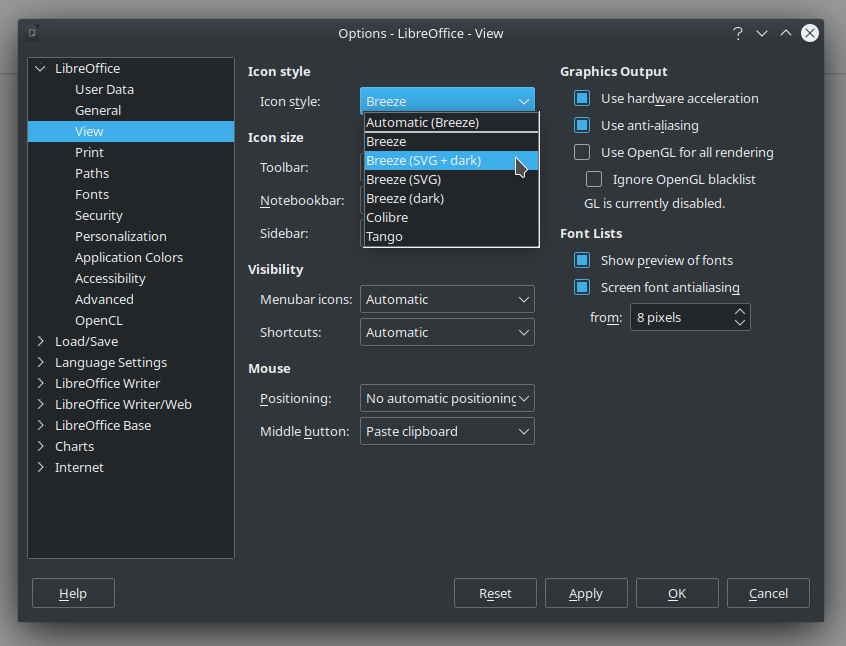
LibreOffice – How To Change Icons to a Darker Theme
I prefer darker themes for my desktop environment (Kubuntu 20.04) and browser (Brave). For the most part, this isn’t a problem, but it does cause an issue with some applications, including LibreOffice (6.4.4.2). One of the first things I do when I install Kubuntu is switch my desktop environment from the default theme (System Settings…
-
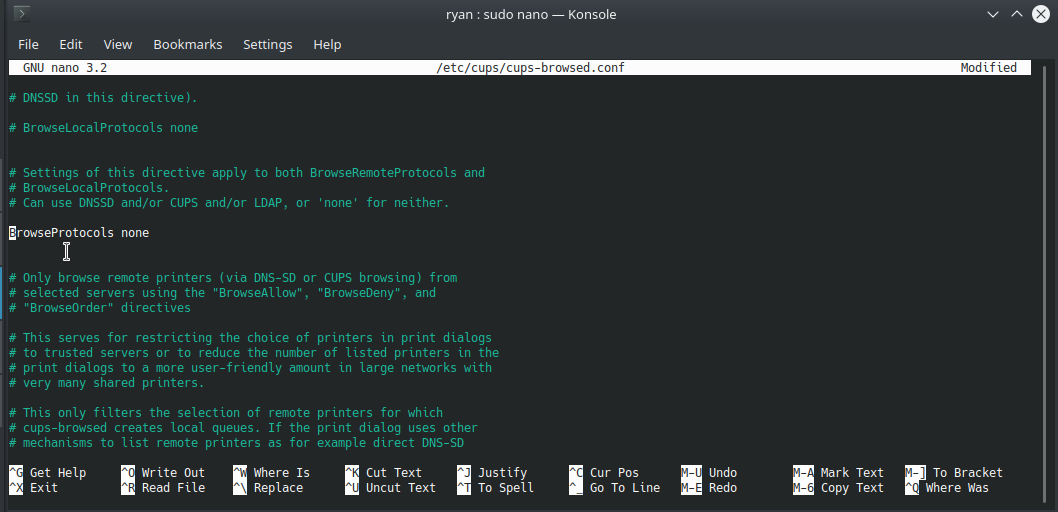
Linux/Kubuntu – Disable Network Printer Auto Discovery
I don’t know when Kubuntu started automatically discovering printers on networks and then adding them to my list of printers, but it is a problematic feature in certain environments – like universities (where I work). I set up my home printer on my laptop easy enough. But, whenever I open my laptop and connect to…