Tag: PDF
-

Redacting PDFs on Linux
I had an odd situation pop up where I needed to redact a PDF. It wasn’t anything nefarious or super exciting, but it did involve a complicated PDF that included images and tables in addition to text. In figuring out how to redact the PDF, I ended up learning a few things and thought it…
-
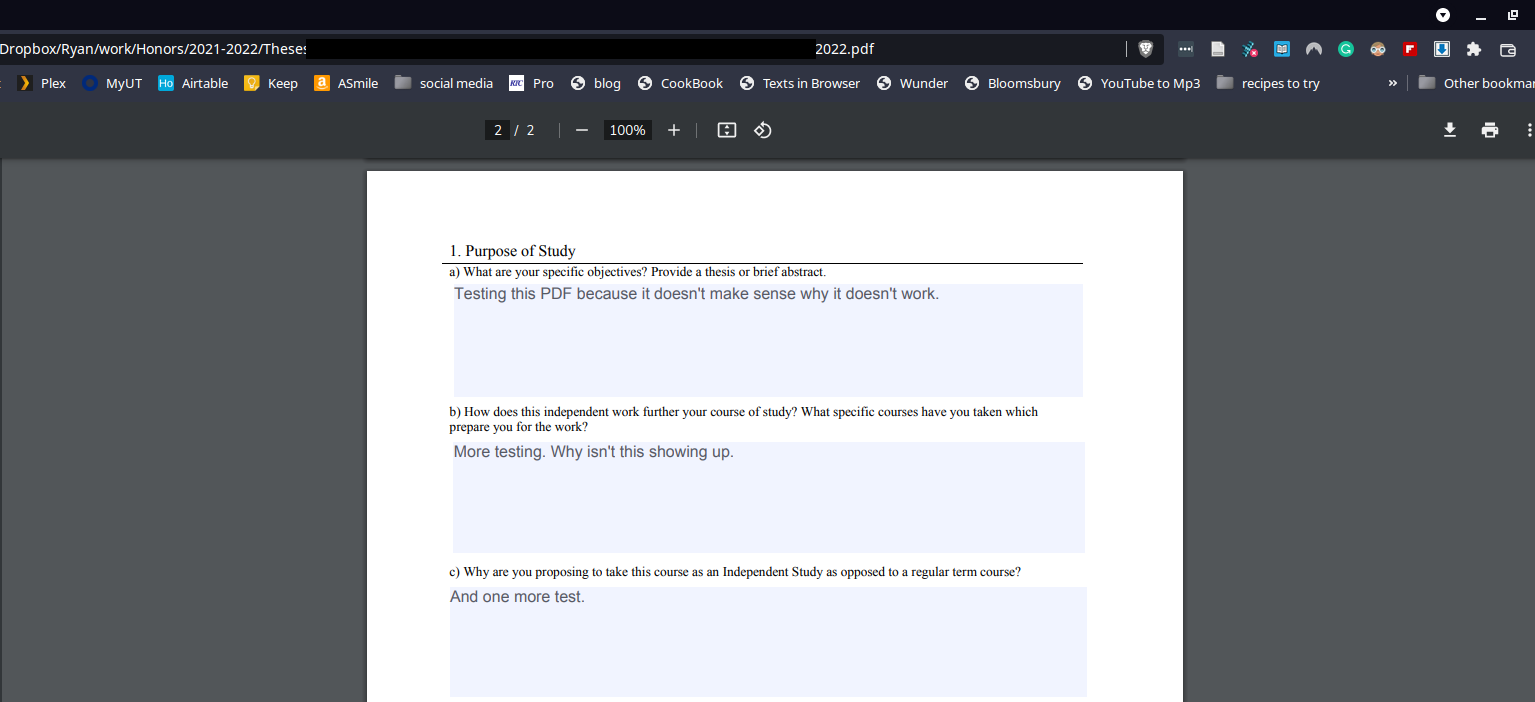
How To Fix PDF Forms Not Showing Contents in Okular (Linux)
I have had this problem happen twice now, and I don’t know exactly what is causing it, but I found a solution. Here’s the situation… I received a PDF that has forms. Typically, that isn’t a problem as Okular is able to open most PDFs with forms and show both the forms and what has…
-
Linux – OCR PDF
One of the few tasks I have not been able to do on Linux since I switched over from Windows more than a decade ago is optical character recognition (OCR) of PDF documents. I work with a lot of PDFs. Most of them were digital documents to begin with and the text is readily selectable.…
-
R (Linux) – creating a wordcloud from PDF
On my professional website, I use wordclouds from the text of my publications as the featured images for the posts where I share the publications. I have used a website to generate those wordclouds for quite a while, but I’m trying to learn how to use the R statistical environment and knew that R can…
-
LibreOffice: Printing with Comments in Margins
UPDATE: As of 12/15/2015, LibreOffice 5.0 broke this feature. See here. This should be fixed as of LibreOffice 5.0.5. I do a lot of my grading in my classes electronically. As a LibreOffice user, one issue I’ve had with the software is that I haven’t been able to insert comments into the document and then…
-
Linux – Fixing PDFs opening in GIMP in Firefox/Zotero (instead of Evince or Okular)
I’m not exactly sure why, but with the latest Firefox updates, every time I download a PDF using Firefox or try to open one using Zotero integrated with Firefox, the PDF opens in GIMP. This didn’t used to happen, but it’s really annoying. It’s doubly annoying since you can’t solve it inside Firefox. It would…