One of the few tasks I have not been able to do on Linux since I switched over from Windows more than a decade ago is optical character recognition (OCR) of PDF documents. I work with a lot of PDFs. Most of them were digital documents to begin with and the text is readily selectable. However, the occasional need arises when I either have to scan something myself or I receive a document that does not have selectable text and is just an image. Up until now, I have kept a software package on a Windows virtual machine (in Virtualbox) specifically to OCR PDFs on the rare occasion when I need to do that. But, I think I can safely move past that thanks to recent advances in OCR on Linux.
I scanned a chapter I wrote in a book recently. The scan looked good (especially after I used Scan Tailor’s Dewarping feature to flatten the pages).

I then converted the TIF files from Scan Tailor into PDF files, put them in the correct order, and was ready to OCR them in the software I used in Windows. However, my virtual machine was giving me some issues and required me to install some updates that were going to take a while (’cause, Windows!). I got the updates started, then realized that I hadn’t checked to see if any progress had been made on OCR on Linux for quite a while (probably a couple of years). A quick Google search landed me on Stack Exchange (where I seem to spend a lot of time these days). There, I found two new options for OCR on Linux.
The first option was a command line program called “ocrmypdf.” That sounds like a dream! I quickly installed it on my Kubuntu machine:
$ sudo apt install ocrmypdfA number of additional packages were installed as well. Once it was installed, I gave it a whirl. The command is pretty easy. Navigate to the directory where you have your PDF you want to have recognized then type in the following:
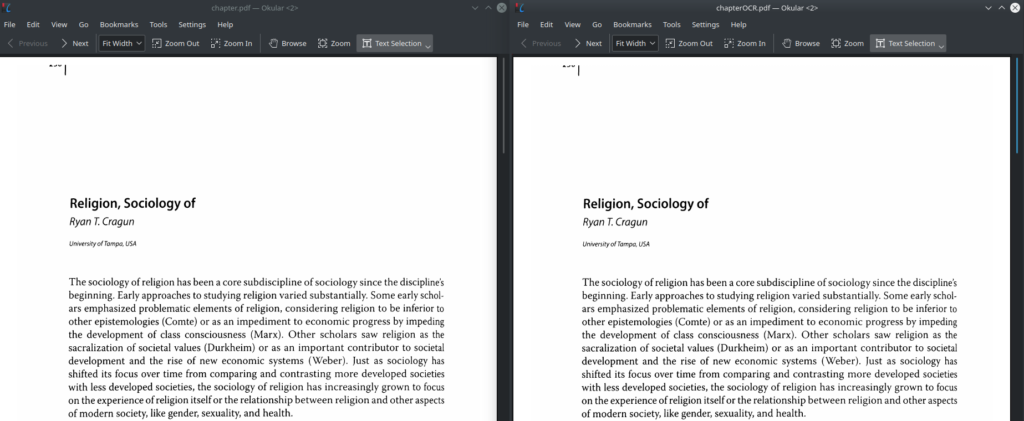
$ ocrmypdf input.pdf output.pdfMy initial PDF (on the left below) was 14 mb in size and looked fine, but I couldn’t select the text – it was just an image. With a quick command, I ran it through the “ocrmypdf” program and got out a nearly identical PDF that was smaller (just 9 mb) and allowed me to select the text (image on the right below).

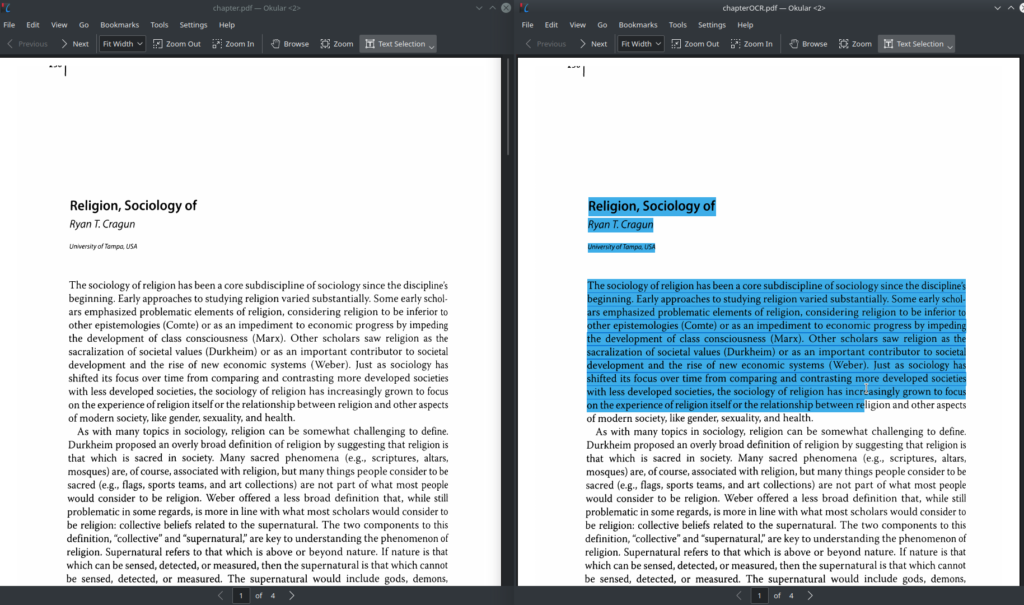
In the next image, you can see that I can select the text in the OCRd image:

Finally, the real question is, how accurate is the OCR? The image below shows the OCR document next to the text:

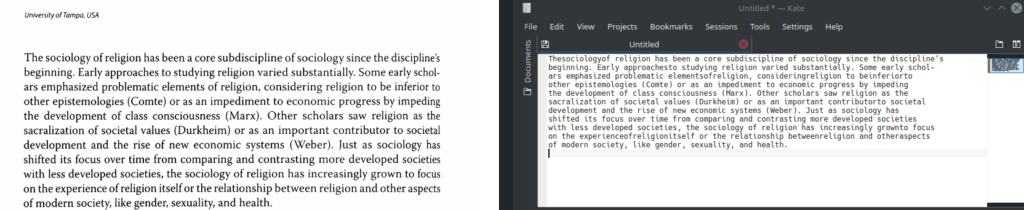
As you can see, this isn’t award-winning software. It’s probably 80 to 90% accurate. But that is more than sufficient for what I need most of the time. And, FOSS, I’ll take it. My rating: 8 out of 10. But given the speed with which I can do this, I’ll absolutely be using this over the old software I was using on a virtual machine before.
On the same page where I found “ocrmypdf,” there was mention of another software package: “ocrfeeder.” Since I had been dreaming of this kind of software for ages, I figured I’d give it a spin as well. I downloaded “ocrfeeder” quickly:
$ sudo apt install ocrfeederI then tried to pull up the GUI… And… Nothing. Perhaps I needed to reboot. Not sure. But “ocrfeeder” didn’t seem to be working on my install (Kubuntu 18.10) when I tried to run it.
![]()
