Category: technology
-
3D Printing Flexible PLA or TPU on Bambu A1 Mini
I had an idea for a print that required flexible filament. The go-to flexible filament is TPU, but I was going to use the print with food, so I looked around for something that I thought would be safer with food and found Flashforge’s flexible PLA. I was excited to try out this print. Once…
-

National Youth Leadership Forum-Engineering & Rice Elite Tech Camp
I posted previously about National Youth Leadership Forum (NYLF) and its extremely expensive summer camps. In that post, I detailed what the camps included and that, from my perspective as a college professor, the camps did not seem worth the money involved. Of course, I cannot call these camps “scams” because you are getting something…
-
Converting EPUB to Mp3 on Linux
I read a lot. It’s part of my job. But I also have times when I have to be physically up and about and could listen to an audiobook (e.g., mowing the lawn). I typically listen to podcasts at those times, but I do have some e-books I’d like to listen to that don’t have…
-

Linux – Adding BPM to ID3 Tags
I spent the better part of a year (in my spare time) organizing my music collection. With my music carefully organized and accurately tagged, I found myself wanting the Beats Per Minute (BPM) for some of my music and realized that BPM can be included in the ID3 tags of MP3 files or the Vorbis…
-

R – Combining Data from Two Variables
(NOTE: This was done in R 4.3.1 using RStudio 2023.03.0.) Here’s the scenario: I have a variable (V1) from Country A with roughly ~1,000 responses that measures religious affiliation with the following options: To be clear, there are no responses to V1 from the participants in the other country (Country B), only from individuals from…
-

ChatGPT – checking for personally identifying information
I recently hired a panel survey company to conduct surveys in several countries around the world. With some of the questions, we gave participants the option to select “other” and then fill in the blank. Given the ethics approval that we have for the data, we are not allowed to retain any data that could…
-
ZFS – disk upgrade/replacement
I built my own Network Attached Storage (NAS) computer a few years ago but have been looking for an opportunity to upgrade the hard drives so I have more space. Leading up to Black Friday, I found a deal for 10TB drives that finally led me to pull the trigger (roughly $80 per drive). They…
-
NoMachine Freezing on Xubuntu 22.04
I have a headless fileserver that runs XFCE (Xubuntu). I recently reformatted the operating system (transferring my files in a ZFS raid to the new operating system rather seamlessly). But the software I use within my local network to access the fileserver, NoMachine, started having problems. Basically, I could access my machine, but the NoMachine…
-
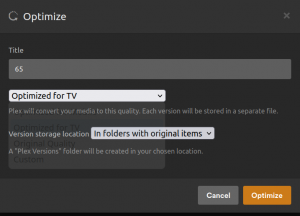
Plex – Video Optimization & Converted Files Permissions
I was traveling with my wife and son, staying at an AirBnB a few states away from home, and wanted to watch some videos from my Plex server (server software version: 1.32.5.7349) using an Amazon Fire Stick on a Samsung TV. When I tried to play the videos using the Plex app on the Fire…
-
Nexis Uni – Date Search Limited to 1 Year, No Issue Browsing, and No Obituaries
I’m a college professor. As a result, I have access to a number of research resources that most people don’t have, including my university’s library, which subscribes to numerous databases to help me and my colleagues (and our students) with our research. I was looking for some very specific information from the Los Angeles Times…